advanced8 Bytes15m / Byte
Future of AI Inference
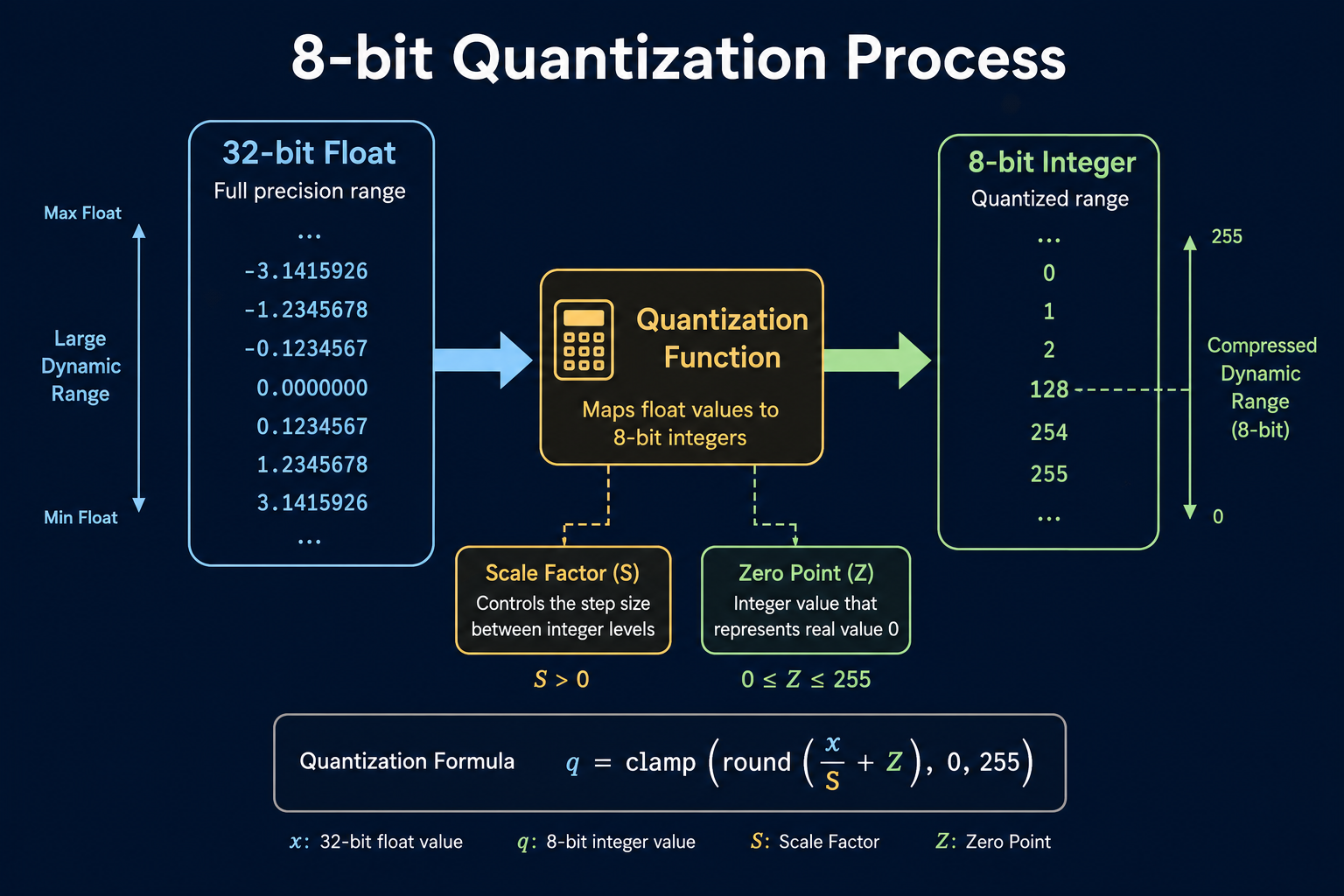
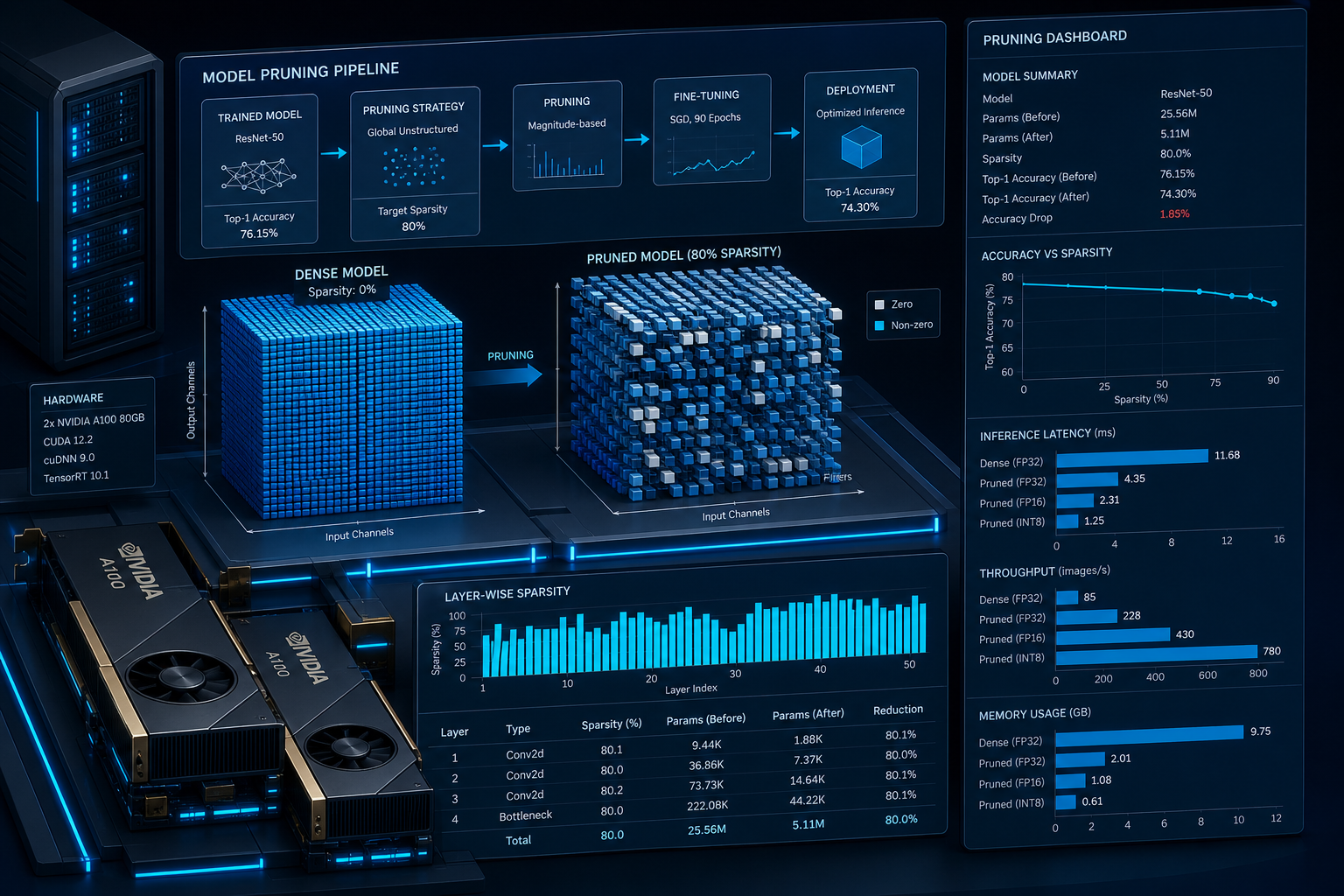
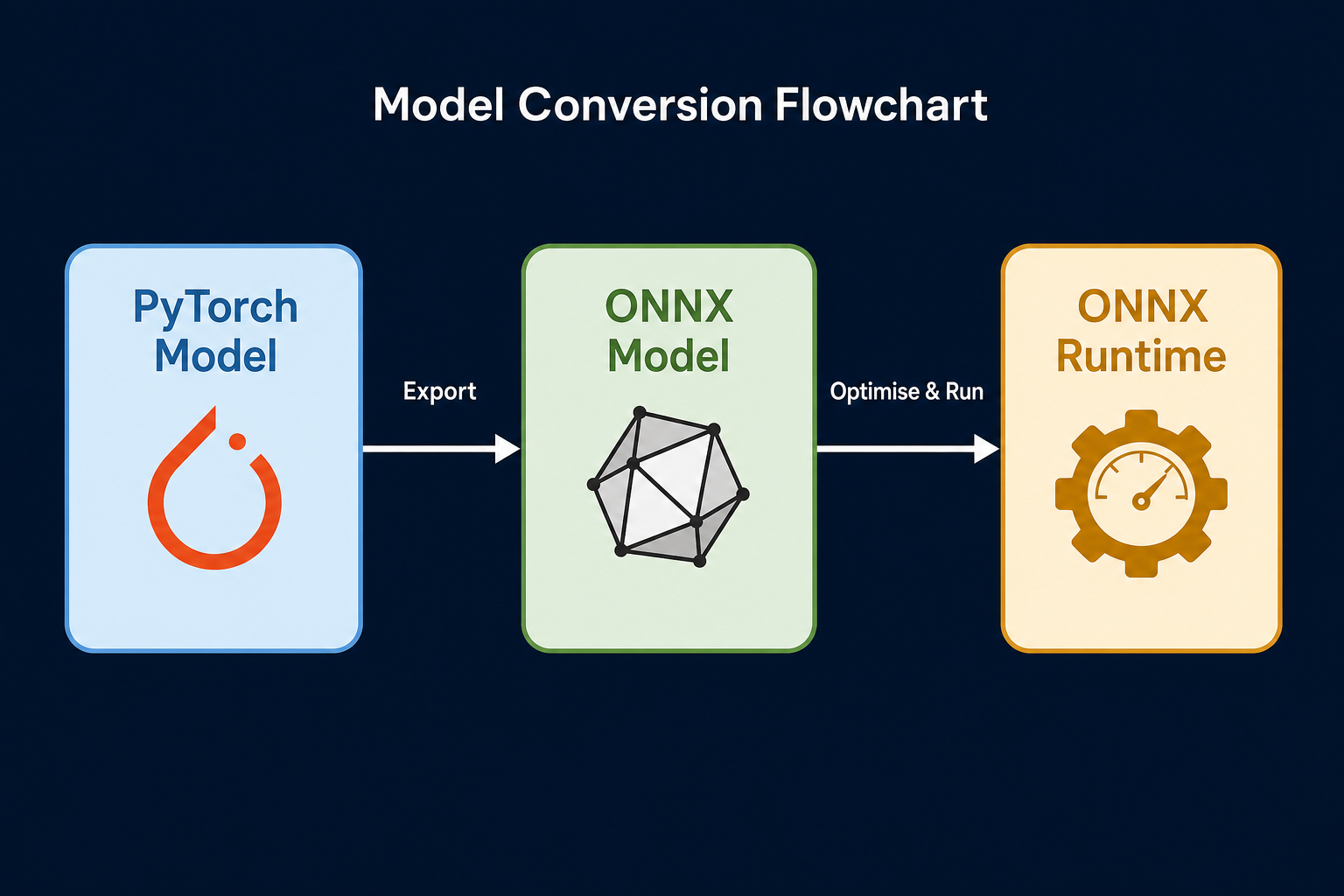
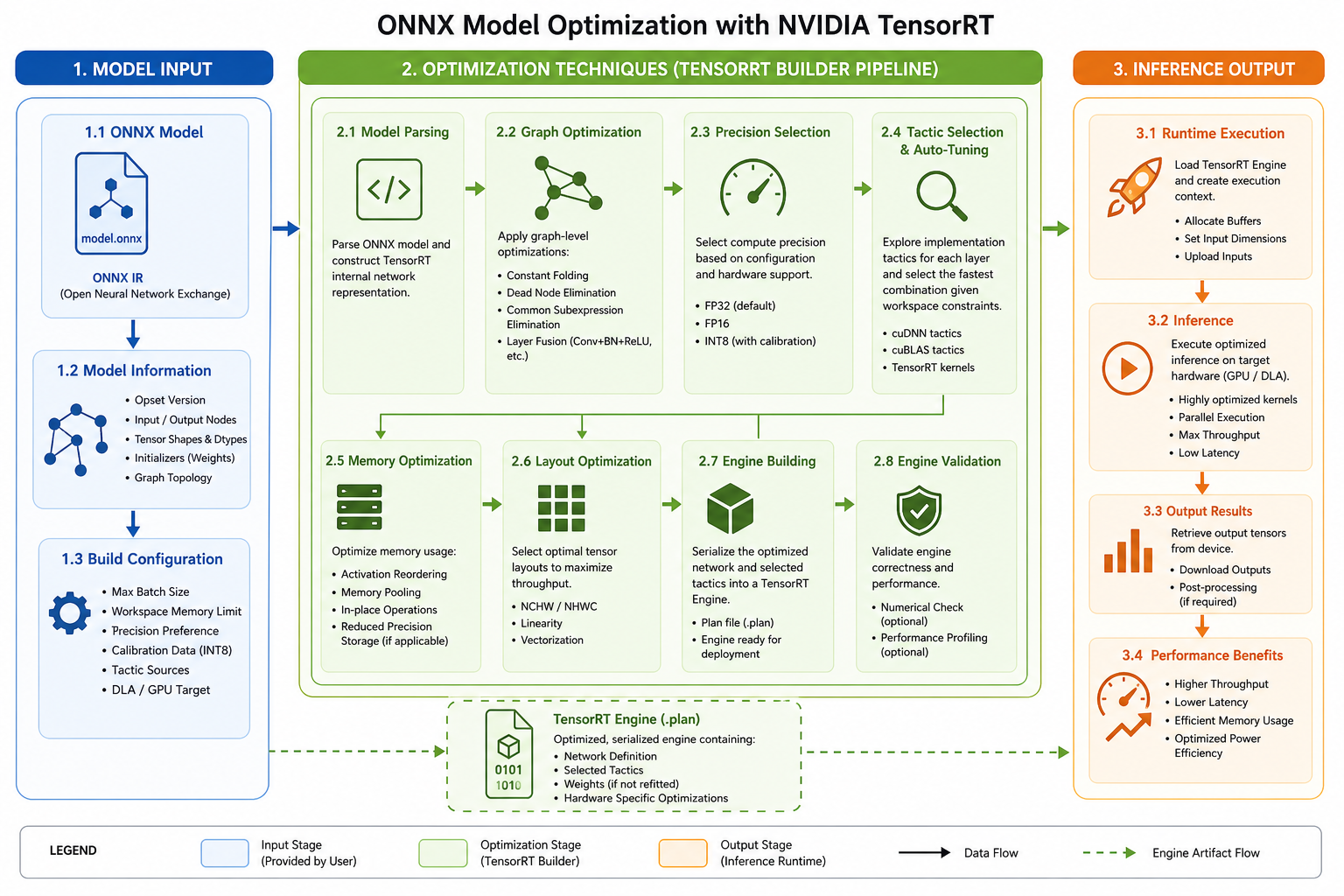
This course details the critical techniques for optimising AI model inference performance. Learners will understand how to apply quantization, model pruning, and hardware-specific acceleration to significantly reduce latency and computational cost for deploying large language models and other AI systems. After completing this course, you will be able to diagnose inference bottlenecks and implement effective strategies using tools like ONNX Runtime and NVIDIA TensorRT.

Lessons
8
Price
Free
Course Curriculum
What you'll learn
4 Modules
8 Lessons
~40m total
Ready to start learning?
Get unlimited access to this course and 50+ others with our Pro subscription.
Includes 7-day money back guarantee. Cancel anytime.
— You might also like